How I use Kubernetes ConfigMaps to manage configurations
Posted on 18 Aug 2020
This is the third article of the Getting Started with Kubernetes series. Here I would like to explain how to manage application configuration with Kubernetes ConfigMaps.
The “Anatomy” of an Application
Whatever application has usually three layers:
- Presentation
- Logic
- Data
Presentation and Logic usually are in the binary code that should never change from one deployment to another. What usually changes is the data. With the term data, we essentially mean the data itself and the configuration. For an application that follows the 12-Factor guidelines, it is essentials that configuration is separated by binary code and data.
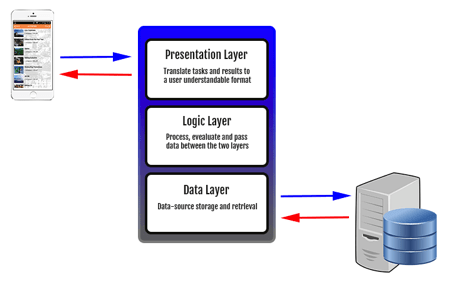
Photo from https://www.wots.mobi
Kubernetes manages configuration with ConfigMaps. In the next sections, I will explain what a ConfigMap is, how to create and use it in your applications, how to mount it in volumes, or use them as environment variables.
What is a ConfigMap in Kubernetes?
In this article, I defined a ConfigMap as a key-value dictionary you can create and add to a Kubernetes cluster whose Pods can reference later.
Why would you use a ConfigMap in Kubernetes?
According to the 12 Factor app, good application design separate configuration from the data and binary code. Kubernetes uses ConfigMaps to achieve this result. A ConfigMap stores configuration settings for your code, it stores connection strings, public credentials, hostnames, URLs, and much more.
The benefit of this separation is that you can associate multiple ConfigMaps to a Pod for different deployments (development, staging, production, etc.) or even change it at runtime without any code change or new deployments.
How does ConfigMap work?
The following steps summarize how ConfigMap works in Kubernetes and the figure below shows the process graphically:
- Create multiple ConfigMaps, one for each environment.
- Add a ConfigMap to the Kubernetes cluster.
- Containers in the Pod reference the ConfigMap and use its values.
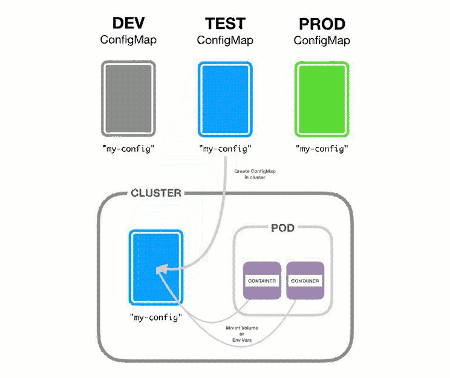
Photo from https://matthewpalmer.net
How to create and add ConfigMaps to clusters?
Using YAML file
In this article, I showed how to define a ConfigMap for an application that contains database connection parameters for database services. Here the example:
apiVersion: v1
kind: ConfigMap
metadata:
name: db-config
namespace: default
data:
connection.properties: |
db.name=mydb
db.port=5432
db.user=myuser
db.password=mypassword
You can use the following command to create the ConfigMap from the YAML file in the default namespace:
kubectl apply -f YAML
As we know from the first article, namespaces are the way Kubernetes manages multiple virtual clusters on a single physical cluster. In our example, we add the ConfigMap to the default namespace.
Using command line
If you have a folder DIR with one or more configuration file or a single file FILE, you can create a ConfigMap from them with kubectl command line:
kubectl create configmap NAME --from-file=DIR or FILE --namespace=default
On both the examples, if you don’t specify a namespace (–namespace is an optional parameter) the ConfigMap is associated with the default one.
There is another way to create ConfigMaps using the kubectl create configmap command. Use literal key-value pairs defined on the command line with
kubectl create configmap db-config --from-literal=key1=value1 --from-literal=key2=value2
You can get more information about this command using kubectl create configmap –help.
How Pods reference ConfigMaps?
In the figure above, you can notice that Pods can reference the ConfigMap in two ways:
- Environment variables.
- Mount volumes.
How Pods reference ConfigMaps with environment variables?
There are basically two ways to reference ConfigMaps with environment variables:
Define the environment variable and get its value from the ConfigMap Load all the key-value pairs from the ConfigMap and use them as environment variables. The following is a YAML example for the first method, where the value of db.user property in the db-config ConfigMap is assigned to the DB_USER_ENV environment variable:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image:x.y.z
env:
- name: DB_USER_ENV
valueFrom:
configMapKeyRef:
name: db-config
key: db.user
This is an example of the second method, where all the properties of the db-config ConfigMap are read and used as environment variables:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image:x.y.z
envFrom:
- configMapRef:
name: db-config
How Pods reference ConfigMaps with mount volumes?
Defining the ConfigMap in YAML and mounting it as a volume is the easiest way to use ConfigMaps.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
volumes:
- name: my-volume
configMap:
name: db-config
containers:
- name: my-container
image: my-image:x.y.z
volumeMounts:
- name: my-volume
mountPath: /etc/config
In this example, you can see that the db-config ConfigMap is defined as a volume (my-volume). Then this volume is mounted under the /etc/config folder creating the connection.properties file in it. Create and add this Pod to the cluster using the kubectl apply command (see above). Attach to the created Pod using kubectl exec -it my-pod sh. Then run ls /etc/config/ and you can see the connection.properties* file. Use the cat command to look at the contents of each file and you’ll see the values from the ConfigMap.
What’s next?
In this article, we learned how to manage application configuration using Kubernetes ConfigMap. However, in the connection.properties file we have a password that is sensitive data (db.password). Kubernetes manages them with Secrets, a new concept that we will analyze in the next article.

