
Amazon Integrated Services (part 1)
Posted on 22 Jan 2021
In this article, I am going to start my overview of the Amazon Integrated Services trying to explain my understanding of the following services:
- Lambda
- Beanstalk
Before reading this, make sure you read this.
Lambda
Lambda is the FaaS solution of the Amazon AWS platform. A FaaS solution allows you to run programming functions without managing any server infrastructure. The difference with the PaaS solution is that only code is under the responsibility of the end-user while the Cloud platform manages the whole application stack included the data.
The benefit to use the Lambda service is that you only take care of the code to run when a given event occurs. The Cloud platform manages everything else like the server infrastructure, its scalability, the logging, and so on. CloudWatch can monitor your code so you know everything is going on with your application. Amazon Lambda supports a lot of programming languages like Node.js, Java, C#, Python, etc.
As said above the code running in Lambda always run in response to an event like an HTTP request, an SNS notification, and others.
Deploy a Lambda application is very easy because you only need to deploy the code and configure it to run when a given event occurs.
Lambda scenario example
Let’s consider the following scenario. We have a mobile application that takes a photo and automatically upload them on S3 bucket and they need to be cropped. Whenever the application uploads a photo on the S3 bucket we create an event that will run the Lambda code that takes the photo and crop it storing it again on the same bucket.
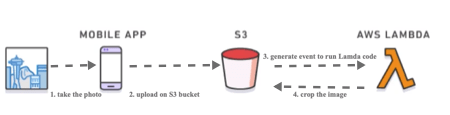
The customer only needs to create the crop code and upload it on the AWS Lambda service, then he needs to create a CloudWatch event to generate an event every time a photo is uploaded on a given bucket and associate with our Lambda code.
The AWS platform will manage the data storage that in our example is the S3 service. If for some reason the number of user increase and a lot of photos is uploaded, the code will be called a lot of time and the service automatically scale the infrastructure to satisfy the requests.
When you create the function you can write the code, define the memory to allocate, define the environment variable, specify the execution role, and much more.
There are a lot of scenarios where you can use the Lambda service, for example, image processing, automatic backups, notifications, IoT, data aggregation, log processing, Data Warehouse ETL, mobile backends, web backends, and others. You can think of Amazon Lambda as a mechanism to let AWS services cooperate to achieve a goal.
Elastic Beanstalk
Elastic Beanstalk is the Amazon Platform as a Service (PaaS) solution. PaaS is one of the service models of Cloud Computing and its basic idea is to let the customer quickly develop its application without managing the infrastructure (i.e. servers, network, disks, operating system, programming language framework, scaling). The customer only takes care of the application and the data, the platform manages everything else.
In the figure below, the Application Service layer is basically the framework (the runtime environment) where the application runs. For example, if your code is Java the application service is the Java Virtual Machine (JVM) that runs the compiled version of that code. The green box has the label “Your code” but this includes the data and configuration too, which must be managed by the customer.
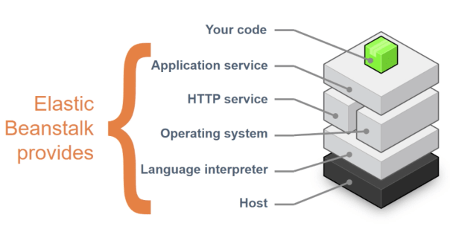
Photo from AWS Cloud Practitioner Essentials (2nd Edition) course
The basic idea is that the developer develops the code and uploads it on a repository in the platform. This one will automatically compile and deploy the code on the server in a way completely transparent to the developer. The application will be accessible via web or API to the end-user. All the complexity to manage the infrastructure is removed.
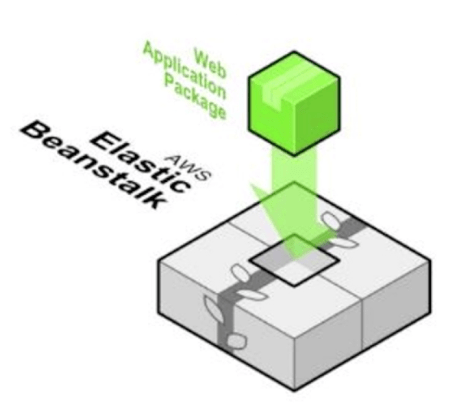
Photo from AWS Cloud Practitioner Essentials (2nd Edition) course
What you can do on Elastic Beanstalk?
You can choose the following options:
- instance type, basically the programming framework you needs for your application (Ruby, Java, Java with Tomcat, Node.js, PHP, Python, Go, containers, etc);
- database, you can attach a database to your application;
- auto-scaling, scale up and down the application, for example, the default, max, and min number of instances;
- update, update your application;
- logs, access to the application logs;
- HTTPS, configure HTTPS on the load balancer.
Application lifecycle
The following figure summarizes the application lifecycle. The developer develops the code and uploads it on a repository, then it creates the application instance in Elastic Beanstalk and associates that repository to it. Elastic Beanstalk prepares the environment for the code, depending on the programming language it instantiates a server with the OS and runtime framework to deploy the code in it. The developer manages the environments via monitoring to check that everything is ok. The developer can update the application at whatever moment by simply uploading the code changes into the repository.
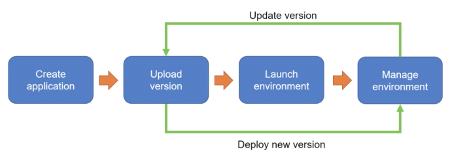
Photo from AWS Cloud Practitioner Essentials (2nd Edition) course
Conclusion
In this article, we talked about the Lambda, and Elastic Beanstalk services. In the next article, we will continue our overview with the other four services.

